

Το Ίδρυμα Mozilla πρωτοπορεί και μας καλεί να συμμετάσχουμε στη δημιουργία μίας ανοιχτής βάσης φωνητικών δεδομένων που θα είναι διαθέσιμη για όλους.

Ως γνωστόν, ο άνθρωπος διαθέτει έναν βιολογικό μηχανισμό που του δίνει τη δυνατότητα να παράγει ήχους. Αυτό ονομάζεται «φωνή» και χρησιμοποιείται στην επικοινωνία μέσω της ομιλίας. Αν και ο καθένας μας έχει διαφορετική φωνή -κάτι που εξαρτάται από διάφορους γενετικούς παράγοντες- ο τρόπος παραγωγής της ομιλίας ανάμεσα στους ανθρώπους είναι ίδιος. Θα μπορούσαμε, λοιπόν να πούμε ότι όλοι μας έχουμε «κοινή φωνή».
Εδώ και αρκετά χρόνια σημειώνονται σημαντικές εξελίξεις στον τομέα της τεχνολογίας που επιχειρεί να προσδώσει σε μηχανές την ικανότητα αναγνώρισης της ανθρώπινης φωνής αλλά και ομιλίας —πιο σωστά, μηχανικής σύνθεσης ήχων που μιμούνται τη φωνή των ανθρώπων.
Τέτοιες υλοποιήσεις φωνητικής λειτουργίας έχουν, πλέον, καθημερινή χρήση στις λεγόμενες «έξυπνες συσκευές» και θα εξελιγχθούν ραγδαία όσο διευρύνεται το IoT. Υπάρχουν ήδη διάφορες (εμπορικές) εκδοχές «οικιακών βοηθών» που μπορούν να προγραμματίζονται ώστε να ανταποκρίνονται σε φωνητικές εντολές και να εκτελούν εργασίες, ενώ κάτι αντίστοιχο θα βρείτε και στο «έξυπνο τηλέφωνό» σας.
Δυσεπίλυτα προβλήματα και εταιρικά εμπόδια
Ωστόσο, η σχετική τεχνολογία δεν έχει ακόμα καταφέρει να επιλύσει σημαντικά προβλήματα, όπως είναι η πολυπλοκότητα της ανθρώπινης ομιλίας (λέξεις, προτάσεις, ηχόχρωμα, έννοιες) αλλά και οι διαφορετικές γλώσσες.
Ακόμα και τα Αγγλικά (Αμερικανικά, για να ακριβολογούμε), που είναι η βάση όλων αυτών των φωνητικών τεχνολογιών, δε βρίσκονται στο επιθυμητό στάδιο ως προς τη σύνθεση και την ανάλυση της ομιλίας, και δεν είναι λίγες οι περιπτώσεις όπου η μηχανή αδυνατεί να καταλάβει τι ζητήσαμε ή καταλαβαίνει λαθεμένα.
Θέλουμε να επιτρέψουμε την ελεύθερη και δημόσια διάθεση των φωνητικών δεδομένων και να διασφαλίσουμε ότι τα δεδομένα αντιπροσωπεύουν την ποικιλομορφία της ανθρωπότητας.
Αν και οι εταιρείες του χώρου συγκεντρώνουν συνεχώς πλήθος φωνητικών δεδομένων (σ.σ. όχι πάντα με θεμιτούς τρόπους), δεν τα μοιράζονται ευρύτερα και έτσι η όποια εξέλιξη στον τομέα παραμένει ελεγχόμενη από αυτές. Το ζητούμενο, λοιπόν, είναι να μάθουν οι μηχανές να κατανοούν επαρκώς την ανθρώπινη φωνή μα και να «μιλούν» ανθρώπινα.
Το Common Voice δίνει φωνή στις συσκευές
Κάπου εδώ έρχεται το έργο «Common Voice» από το Ίδρυμα Mozilla, με στόχο να διδάξει στις μηχανές το πώς ακριβώς μιλούν οι άνθρωποι. Πρόκειται για μία προσπάθεια που βασίζεται στο crowdsourcing (πληθοπορισμός) για τη δημιουργία μίας παγκόσμιας βάσης φωνητικών δεδομένων που δε θα περιορίζεται από πνευματικά ή άλλα δικαιώματα, θα είναι προσβάσιμη από όλους ως Κοινό Κτήμα (άδεια CC-0) και θα μπορεί να αξιοποιηθεί ελεύθερα σε οποιοδήποτε λογισμικό αναγνώρισης ομιλίας.
Βέβαια, για να υλοποιηθεί όλο αυτό απαιτούνται τεράστιες ποσότητες δεδομένων και έμπρακτο ενδιαφέρον, ειδικά από τους ομιλούντες την ελληνική γλώσσα που δεν τυγχάνει μεγάλης απήχησης. Εδώ μπορούμε να βοηθήσουμε όλοι μας, και μάλιστα με δύο τρόπους. Το μόνο που χρειάζεται είναι ένα μικρόφωνο και λίγα λεπτά από τον χρόνο μας.
Η διαδικασία είναι πολύ απλή. Αφού μεταβούμε στην ιστοσελίδα του έργου, μπορούμε να επιλέξουμε πώς θα συνεισφέρουμε.
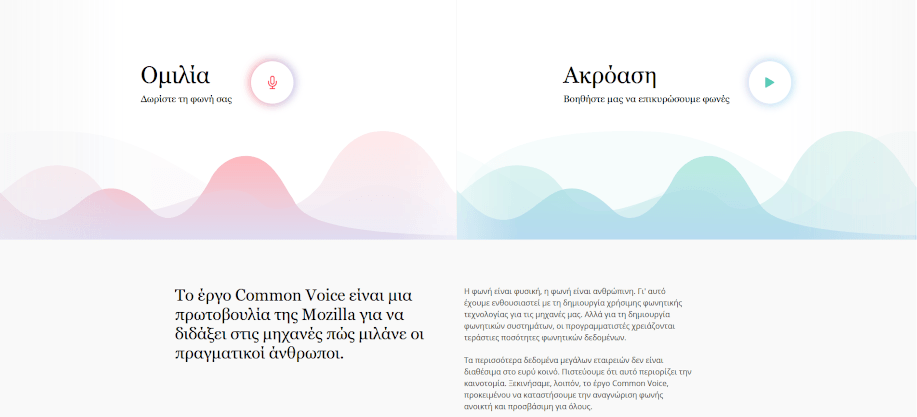
- Διαλέγοντας να δωρίσουμε τη φωνή μας, πατάμε το κόκκινο κουμπάκι στο πλαίσιο «Ομιλία» και έπειτα μπορούμε να διαβάσουμε πέντε ή περισσότερες μικρές προτάσεις οι οποίες θα υποβληθούν για έλεγχο. Εξυπακούεται πως όσο περισσότερες διαβάσουμε, τόσο καλύτερα. Δεν υπάρχει κανένα πρόβλημα αν τυχόν τα Ελληνικά δεν είναι η μητρική μας γλώσσα ή αν μιλάμε με προφορά.
- Αν δεν επιθυμούμε να δημοσιοποιηθεί η φωνή μας, η συνεισφορά μας μπορεί να είναι εξίσου σημαντική με την αξιολόγηση εκφωνήσεων από άλλους ανθρώπους. Πατώντας το αντίστοιχο πράσινο κουμπάκι στο πεδίο «Ακρόαση», θα ακούσουμε μερικές ηχογραφήσεις που μπορούμε να βαθμολογήσουμε με «Ναι» ή «Όχι», ανάλογα με την ορθότητα και την καθαρότητά τους.
Επειδή πρόκειται για το Ίδρυμα Mozilla, θα βρούμε αναλυτικές λεπτομέρειες για την πολιτική απορρήτου και τους όρους χρήσης που συνοδεύουν το έργο, καθώς και μία σειρά συχνών ερωτήσεων που εκτείνονται από τους στόχους του Common Voice μέχρι τον τρόπο με τον οποίο θα χρησιμοποιηθούν και θα διατεθούν τα δεδομένα.
Τονίζεται ότι οποιαδήποτε παροχή χρήσιμων πληροφοριών εκ μέρους μας που θα μπορούσαν να βοηθήσουν στην πληρέστερη ανάλυση των φωνών, όπως η ηλικία και το φύλο μας, είναι απόλυτα προαιρετική, ενώ δεν απαιτείται καν η δημιουργία λογαριασμού για να συμμετάσχουμε στην προσπάθεια. ΠληροφορίαΤο έργο Common Voice προορίζεται να συνοδεύσει τη μηχανή αναγνώρισης ομιλίας ανοιχτού κώδικα που ονομάζεται Deep Speech.
Ας δωρίσουμε τη φωνή μας στις τεχνολογίες του μέλλοντος
Δυστυχώς, η συνεισφορά ελληνόφωνων είναι, επί του παρόντος, απελπιστικά μικρή με μόλις 2 ώρες και 23 λεπτά ηχογραφήσεων και 57 λεπτά επαληθεύσεων, σε σύγκριση με τις 4,7 και 3,8 χιλιάδες ώρες αντίστοιχα για το παγκόσμιο σύνολο. Σίγουρα έχουμε συναντήσει περιπτώσεις απογοήτευσης γιατί η τεχνολογία δε «μιλάει» Ελληνικά. Ορίστε, λοιπόν, η ευκαιρία να αλλάξει αυτό με τη δική μας συμβολή.
Στην εποχή που η τεχνολογία μεταβάλλεται κάνοντας πραγματικότητα όλα αυτά που κάποτε θεωρούνταν φουτουριστικά, είναι σπάνιες οι περιπτώσεις διάφανης ανάπτυξης πρωτοποριακών έργων. Το Ίδρυμα Mozilla μας δίνει τη δυνατότητα να δημιουργήσουμε μαζί μία κοινή και ανοιχτή βάση φωνητικών δεδομένων. Ας βοηθήσουμε τις συσκευές να καταλάβουν τη γλώσσα μας.
Τα φωνητικά δεδομένα στο GitHub
Πηγή άρθρου: https://osarena.net/