

Ένα από τα βασικά επιχειρήματα εκείνων που υποστηρίζουν το Άρθρο 13 της Οδηγίας για τα Πνευματικά Δικαιώματα της ΕΕ , είναι ότι οι άνθρωποι που ισχυρίζονται ότι θα οδηγήσει σε ευρεία λογοκρισία απλώς υπερβάλλουν. Έχουμε εξηγήσει πολλές φορές γιατί αυτό είναι αναληθές και πως το σύστημα αυτόματου φιλτραρίσματος, θα λογοκρίνει αμέτρητα έργα, απολύτως νόμιμου περιεχομένου, επειδή οι αλγόριθμοι κάνουν λάθη. Και όταν γίνονται λάθη σε μεγάλη κλίμακα, συμβαίνουν κακά πράγματα.
Οι περισσότεροι από εσάς είστε εξοικειωμένοι με την έννοια των σφαλμάτων “type 1” και “type 2” στη στατιστική. Αυτά μπορούν να περιγραφούν απλώς ως ψευδή θετικά και ψευδώς αρνητικά. Κατά τη διάρκεια του Σαββατοκύριακου, ο Alec Muffett αποφάσισε να βάλει σε λειτουργία ένα γρήγορο “ψευδώς θετικό” εξομοιωτή για να δείξει τις επιπτώσεις που θα είχε σε κλίμακα το αυτόματo φιλτράρισμα.
Με λίγα λόγια: σε κλίμακα, το “ψευδώς θετικό” πρόβλημα είναι αρκετά έντονο. Χιλιάδες έργα νόμιμου περιεχομένου είναι πιθανό να παρασυρθούν στο χάος.
Χρησιμοποιώντας μια βάση 10 εκατομμυρίων έργων περιεχομένου και ένα επίπεδο ακρίβειας (99,5%) -πολύ υψηλότερο από την πραγματικότητα- και με την υπόθεση ότι 1 στα 10.000 αντικείμενα είναι “κακό” (δηλαδή “παραβιάζει πνευματικά δικαιώματα”) καταλήγει στη λογοκρισία χιλιάδων έργων νόμιμου, που έχει μπλοκαριστεί για να σταματήσει μόνο ένα κομμάτι της παράβασης:

Έτσι, ουσιαστικά, σε μια προσπάθεια να σταματήσουμε 1.000 κομμάτια παραβιαζόμενου περιεχομένου, θα καταλήξουμε να μπλοκάρουμε 50.000 κομμάτια νόμιμου περιεχομένου. Και αυτό είναι με ένα απίστευτο (και απίθανο) 99,5% ποσοστό ακρίβειας. Αν το ποσοστό ακρίβειας των μηχανών φιλτραρίσματος θα είναι στο -πολύ αισιόδοξο- ποσοστό του 90% τα αποτελέσματα είναι ακόμα πιο τραγικά:
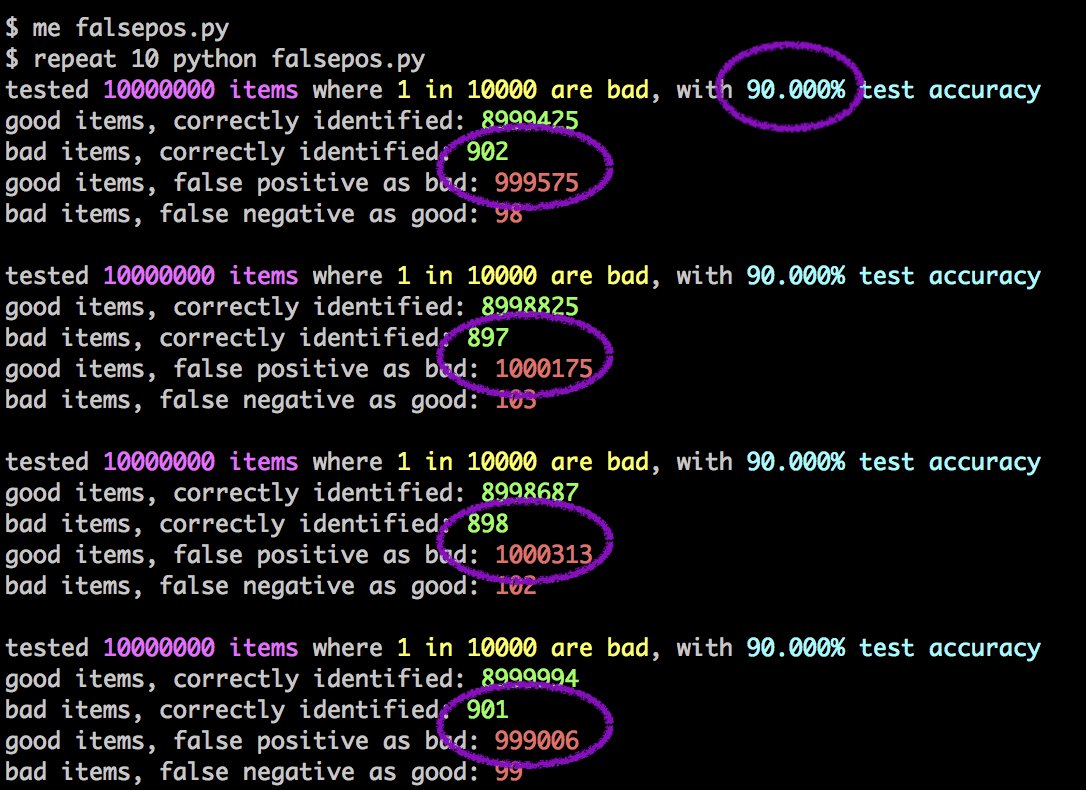
Θα μιλάμε για την κατάργηση ενός εκατομμυρίου νόμιμων κομματιών περιεχομένου για το μπλοκάρισμα μόλις 1.000 παραβατικών έργων.
Φυσικά, μπορούμε να ακούσουμε από τώρα, τις συνηθισμένες αντιρρήσεις, ότι ο αριθμός 1 στο 10,0000 είναι μη ρεαλιστικός (δεν είναι). Πολλοί εκπρόσωποι των βιομηχανιών πνευματικής ιδιοκτησίας, ισχυρίζονται ότι ο μόνος λόγος που οι άνθρωποι χρησιμοποιούν μεγάλες πλατφόρμες όπως το YouTube και το Facebook είναι να φορτώνουν υλικό που παραβιάζει πνευματικά δικαιώματα, αλλά αυτό είναι γελοία λάθος. Είναι στην πραγματικότητα ένα πολύ, πολύ μικρό ποσοστό αυτού του περιεχομένου. Και, θυμηθείτε, βεβαίως, το άρθρο 13 θα ισχύει ουσιαστικά για κάθε πλατφόρμα που φιλοξενεί περιεχόμενο, ακόμη και εκείνες που χρησιμοποιούνται σπάνια για παραβίαση.
Αλλά, μόνο για όσους πιστεύουν ότι η παράβαση είναι πολύ πιο διαδεδομένη από ό, τι πραγματικά είναι, ο Muffett έτρεξε επίσης τον εξομοιωτή με ένα σενάριο στο οποίο 1 από τα 500 κομμάτια περιεχομένου παραβιάζει πνευματικά δικαιώματα με (την ακόμα πιο αδύνατη) ακρίβεια του 98,5% . Τα αποτελέσματα ακόμα πιο καταστροφικά:
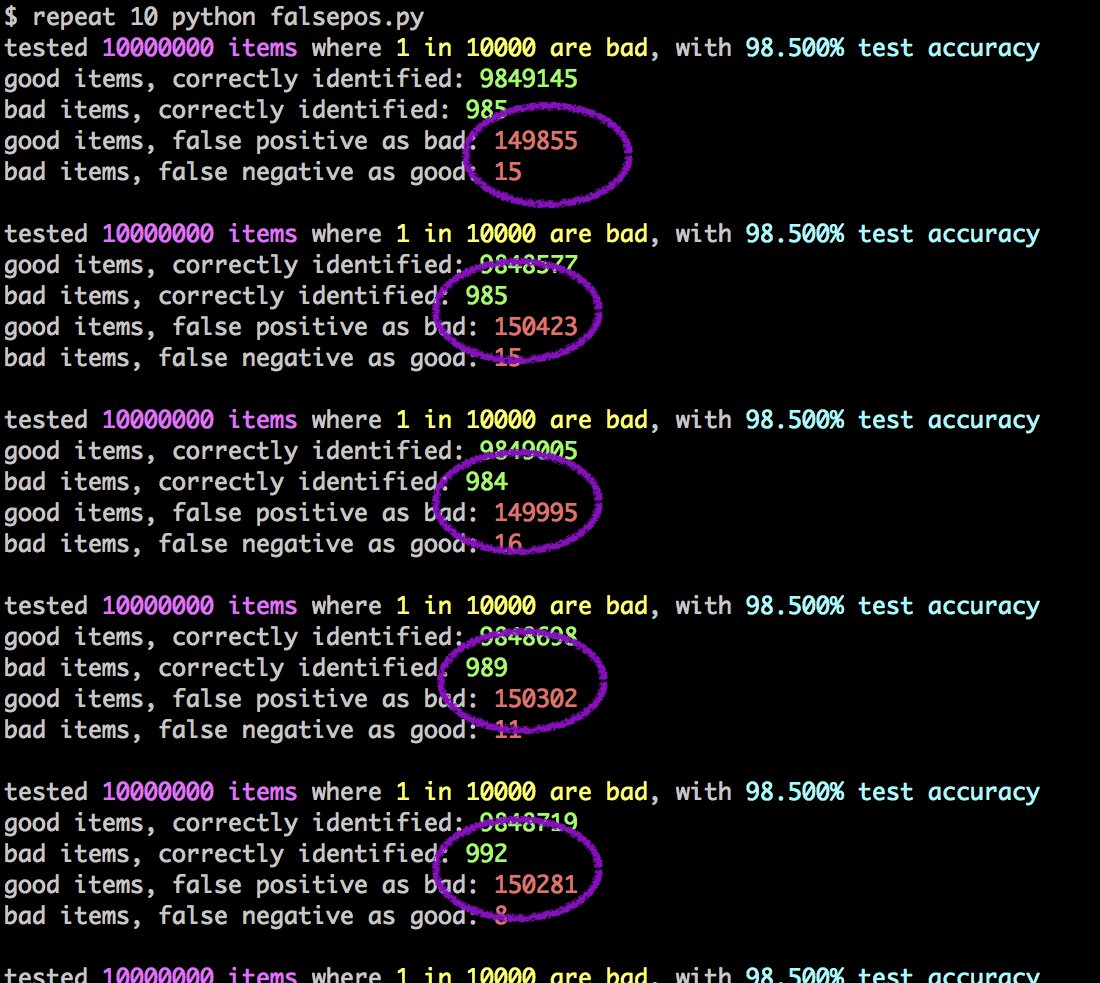
Σε αυτό το εντελώς μη ρεαλιστικό σενάριο με πολύ μεγαλύτερες παραβάσεις από ό, τι στην πραγματικότητα, και με ποσοστά ακρίβειας πολύ πιο πάνω από την πραγματικότητα, καταλήγουμε να μπλοκαριστούν 150.000 αντικείμενα που δεν παραβιάζουν κανένα πνευματικό δικαίωμα … μόνο και μόνο για να σταματήσουν λιγότερο από 20.000 παραβατικά κομμάτια περιεχομένου!.
Αυτό είναι ένα από τα βασικά προβλήματα που οι άνθρωποι δεν φαίνεται να κατανοούν όταν μιλάνε για φιλτράρισμα περιεχομένου σε μεγάλη κλίμακα. Ακόμα και με απίστευτα υψηλά ποσοστά ακρίβειας, ένα “μικρό” ποσοστό ψευδών θετικών οδηγεί σε μια τεράστια ποσότητα λογοκριμένου περιεχομένου που είναι απολύτως νόμιμο.
Ίσως μερικοί άνθρωποι να αισθάνονται ότι αυτό είναι αποδεκτές “παράπλευρες απώλειες” για την αντιμετώπιση ενός σχετικά μικρού ποσοστού παραβιάσεων σε διάφορες πλατφόρμες, αλλά το να αρνείται ότι θα δημιουργήσει ευρεία λογοκρισία νόμιμου και μη παραβατικού περιεχομένου είναι σαν να αρνείται την πραγματικότητα.
Πηγή άρθρου: https://www.techdirt.com
“1 από τα 500 κομμάτια περιεχομένου παραβιάζει πνευματικά δικαιώματα”:
Η αντίστοιχη εικόνα δείχνει καθαρά “1 in 10000 are bad”, αν και δείχνει το ποσοστό 98,5% ακρίβειας.
Γενικότερα, δεν καταλαβαίνω γιατί χρειαζόμαστε “ένα γρήγορο «ψευδώς θετικό» εξομοιωτή”, όταν το που θα κυμαίνονται τα νούμερα μπορεί να υπολογιστεί ευθέως και πως μπορεί να αντιμετωπιστεί η ρητορική για το αν τα νούμερα αυτά είναι μικρά ή μεγάλα, με προσομοίωση του που κυμαίνονται οι αριθμοί…
Κατά τη γνώμη μου, μετά την παροχή των αναμενόμενων σχετικών *μέσων όρων* για ένα, όμως, *πραγματικού μεγέθους* repository, τα επιχειρήματα έπρεπε να περιστρέφονται γύρω από το τεκμήριο αθωότητας, δηλαδή γύρω από το κατά πόσον θα έπρεπε κάποιος να αποδεικνύει ότι είναι αθώος (δεν είναι ελέφαντας), έναντι του να τιμωρείται μόνο όταν αποδεικνύεται ότι είναι ένοχος!